
上一篇
服务器运维 智能管理:如何设计和实现高效的服务器管理软件?
服务器运维 | 智能管理:如何设计和实现高效的服务器管理软件?
🌙 凌晨三点的警报:传统运维的痛点
想象一下:你是某互联网公司的运维工程师,凌晨三点被服务器负载过高的警报吵醒,你揉着惺忪的双眼登录服务器,发现是某业务线突然流量激增,但自动扩缩容机制未触发,手动调整配置、重启服务、核对日志……一小时后系统终于稳定,而你的咖啡早已凉透。
这样的场景是否似曾相识?
传统运维依赖人工干预,效率低、易出错,且无法应对现代业务对高可用性、快速响应的需求,而智能服务器管理软件,正是为解决这些痛点而生。

🚀 智能管理软件的核心设计原则
自动化驱动,解放人力
- 自动扩缩容:基于Kubernetes等容器编排工具,结合业务负载实时调整资源(如Azure Kubernetes Service在2025年已支持Cilium网络模式,提升扩展效率)。
- 故障自愈:通过预设规则(如“CPU使用率>90%时重启服务”)或AI模型预测故障(如深度学习模型可提前30分钟预警磁盘故障),减少人工介入。
- 批量操作:工具如Fablinker支持通过SSH同时管理数百台服务器,执行命令、部署应用,效率提升10倍以上。
数据可视化,一目了然
- 全景监控:集成Prometheus、Grafana等工具,实时展示CPU、内存、网络等指标,支持自定义仪表盘(如某金融客户通过ServiceDesk Plus将工单响应时间缩短42%)。
- 日志分析:通过ELK(Elasticsearch+Logstash+Kibana)堆栈集中管理日志,结合AI提取关键信息(如“异常登录”“服务崩溃”等关键词)。
安全合规,防患于未然
- 权限管控:基于角色的访问控制(RBAC),确保只有授权人员能操作敏感服务器(如ManageEngine ServiceDesk Plus支持多因素认证)。
- 审计追踪:所有操作自动记录日志,满足《数据安全法》等法规要求(某集团通过此功能通过监管年审)。
可扩展性,适应未来
- 插件化架构:支持通过API接入第三方工具(如集成云监控、CI/CD流水线)。
- 混合云管理:无缝对接AWS、阿里云等公有云,以及私有云环境,实现资源统一调度。
🛠️ 关键技术实现:从理论到代码
智能工单系统(以ServiceDesk Plus为例)
- AI分类与推荐:
# 使用Zia AI处理工单 def classify_ticket(text): intent = zia.predict(text) # 调用AI模型识别意图 return knowledge_base.recommend(intent) # 推荐解决方案 - 多渠道接入:支持邮件、API、Web表单等,统一收敛至工单系统。
预测性维护(基于深度学习)
- 模型训练:
# 使用LSTM预测磁盘故障 model = Sequential() model.add(LSTM(64, input_shape=(timesteps, features))) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam') model.fit(X_train, y_train, epochs=10)
- 实时预警:当预测值超过阈值时,自动触发工单并通知运维团队。
自动化部署(以TableGo为例)
- 低代码生成代码:
// 通过模板生成JavaBean public class ${TableName} { #foreach($field in $fields) private ${field.type} ${field.name}; #end } - 一键部署:结合SSH2连接服务器,执行脚本上传文件、重启服务。
🌐 行业案例:从“被动救火”到“主动预防”
案例1:某金融集团
- 痛点:变更事故率高,监管审计压力大。
- 方案:部署ServiceDesk Plus,集成变更审批流程与CMDB资产图谱。
- 效果:
- 关键系统变更事故率下降65%;
- 工单平均响应时间缩短42%,首次解决率提升至86%。
案例2:某游戏公司
- 痛点:服务器集群管理复杂,玩家投诉卡顿。
- 方案:采用Serein自动化工具,统一管理游戏服务器,支持群服互通与远程控制。
- 效果:
- 服务器部署时间从2小时缩短至10分钟;
- 玩家卡顿投诉量下降80%。
🔮 未来趋势:AI与运维的深度融合
AIOps的全面落地
- 故障预测:通过生成式AI(如GPT-4)分析日志,提前发现潜在问题。
- 根因分析:结合知识图谱,快速定位故障根源(如“网络抖动→API超时→服务崩溃”)。
无服务器架构(Serverless)的普及
- 按需付费:无需管理服务器,代码自动扩缩容(如AWS Lambda)。
- 事件驱动:通过API Gateway触发函数,适用于突发流量场景。
边缘计算与运维的结合
- 本地决策:在边缘节点(如CDN服务器)直接处理数据,减少延迟。
- 统一管理:通过中央控制台监控全球边缘节点,确保一致性。
💡 运维的终极目标是“无感”
高效的服务器管理软件,应像空气一样“存在但不被感知”——业务稳定运行,用户无需关心底层细节,通过自动化、智能化、安全化的设计,运维团队可从“救火队员”转变为“业务赋能者”,让技术真正服务于业务增长。
下一次凌晨三点的警报,或许不会再响起。 🌙→☀️

本文由 业务大全 于2025-08-20发表在【云服务器提供商】,文中图片由(业务大全)上传,本平台仅提供信息存储服务;作者观点、意见不代表本站立场,如有侵权,请联系我们删除;若有图片侵权,请您准备原始证明材料和公证书后联系我方删除!
本文链接:https://cloud.7tqx.com/wenda/672812.html
最新文章
-
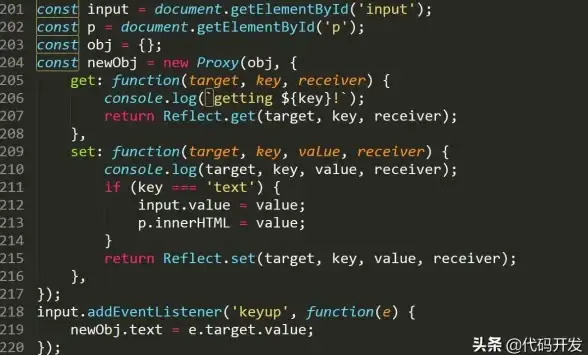
表单校验 数字输入框:elementui input限制只能输入数字并保留两位小数的方法
2025-08-26 -

宴会聚餐想省心?试试订多多APP,商家入驻任你选!
2025-08-26 -
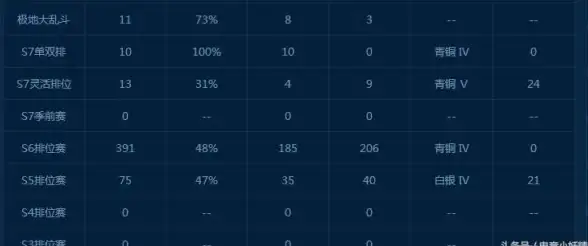
游戏攻略🔥LOL排位段位突然消失解决方法详解
2025-08-26 -

🔥福利爆棚🔥充值返利攻略|暴吵萌厨》删档测试必看秘籍
2025-08-26 -

还在为桌面杂乱烦恼?试试ATV桌面启动器Pro,一键打造极简高效界面!
2025-08-26 -

想拥有独一无二的专属声音?何不用“芊芊妙音app”自由定制你的声线?
2025-08-26 -
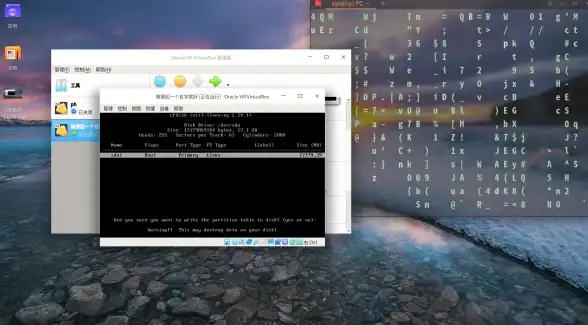
教程 新手必看:凤凰系统安装全过程演示指南
2025-08-26 -

游戏对比⚡实力解析 一刀传世符与雷哪个好用?
2025-08-26

发表评论